Difference between revisions of "iRefScape 0.7"
| Line 237: | Line 237: | ||
===Node Attributes=== | ===Node Attributes=== | ||
| + | |||
| + | Each node represents a distinct amino acid sequence (protein) from a distinct organism (taxon id). Each of the attributes below, provide additional information about the node. Although each node is distinct, a graph produced by iRefIndex may contain multiple nodes that are related proteins (i.e., splice isoform products from the same gene). These nodes will all have the same "i.canonical_rog" and i.canonical_rogid" feature values. See notes below. | ||
Node attributes that can be lists of items (like i.UniProt) will have a corresponding attribute called i.[attribute name]_TOP (e.g. i.UniProt_TOP) that is the first item of the list. | Node attributes that can be lists of items (like i.UniProt) will have a corresponding attribute called i.[attribute name]_TOP (e.g. i.UniProt_TOP) that is the first item of the list. | ||
| Line 294: | Line 296: | ||
===Edge Attributes=== | ===Edge Attributes=== | ||
| − | {| | + | |
| − | + | Each edge represents a distinct primary database record that supports some relationship between the two incident nodes. So, if an interaction between two proteins has been annotated by two databases (or twice by the same database) then two edges will appear between those two protein nodes. | |
| − | + | ||
| − | + | {|class="wikitable" style="text-align:left" border="1" cellpadding="5" | |
| − | + | !width="50" align="center" style="background:#f0f0f0;"|Attribute name | |
| + | !width="50" align="center" style="background:#f0f0f0;"|Data type | ||
| + | !width="50" align="center" style="background:#f0f0f0;"|Example value | ||
| + | !width="400" align="center" style="background:#f0f0f0;"|Description | ||
| + | |- | ||
| + | | ID||String||10121899 (2771704(40952)) 13911416||This is a unique identifier for the edge assigned by Cytoscape (no two edges would have same ID). See i.rig and i.rigid for unique identifiers for the edge assigned by iRefIndex. | ||
| + | |- | ||
| + | | I.PMID||Integer||14605208||Publication identifier of the publication where the interaction represented by the edge mentioned. Right click on this entry and select: Search [PMID] on the web -- Entrez -- Pubmed for more details on the publication. | ||
| + | |- | ||
| + | | i.bait||Integer||13911416||Node ID for the protein that was used as a bait in this experiment. Only applicable where the experimental system (see i.method_name) used to support this relationship was a bait-prey system (e.g. two hybrid). | ||
| + | |- | ||
| + | | i.canonical_rig||Integer||27799||See notes for i.rig edge feature. This is the rig constructed for the interaction using its canonical rogs. Use a web browser to query http://wodaklab.org/iRefWeb/interaction/show/27799 (where 27799 is the canonical_rig) to retrieve more information on this interaction and equivalent source interaction records. | ||
| + | |- | ||
| + | | i.experiment||String||Giot L [2003]||A short label for the experiment where this interaction was found (usually contains authors names). | ||
| + | |- | ||
| + | | i.flag||Integer||1||Used by iRefIndex plugin to control display of edges (0- the representative edge, used in edge toggle, 1- an edge which will disappear during edge toggle, 2- complex holder edge,6-a path, 7-Edge from or to a collapsed node). | ||
| + | |- | ||
| + | | i.host_taxid||Integer||7227||Indicates the organism taxon id where the interaction was experimentally demonstrated. | ||
|- | |- | ||
| − | | | + | | i.isLoop||Integer||1||Indicates whether the interaction is a self interaction (i.e dimer or possibly multimer of the same protein type). See the source interaction record for details. |
|- | |- | ||
| − | | | + | | i.method_cv||String||MI:0018||PSI-MI controlled vocabulary term id for the method used to provide evidence for this interaction. See http://www.ebi.ac.uk/ontology-lookup/ for more details. The name of the method is also given in the i.method_name feature. |
|- | |- | ||
| − | | i. | + | | i.method_name||String||two hybrid||PSI-MI controlled vocabulary term name for the method used to provide evidence for this interaction. See http://www.ebi.ac.uk/ontology-lookup/ for more details. The term identifer is also given in the i.method_cv feature. |
|- | |- | ||
| − | | i. | + | | i.participant_identification||String||predetermined participant||PSI-MI controlled vocabulary term for the participant identification method used to provide evidence for this interaction. See http://www.ebi.ac.uk/ontology-lookup/ for more details. The identifier for the term is also given in the i.participant_cv feature. |
|- | |- | ||
| − | | i. | + | | i.participant_cv||String||predetermined participant||PSI-MI controlled vocabulary term id for the participant identification method used to provide evidence for this interaction. See http://www.ebi.ac.uk/ontology-lookup/ for more details. The term itself is also given in the i.participant_identification feature. |
|- | |- | ||
| − | | i. | + | | i.type_cv||String||MI:0407||PSI-MI controlled vocabulary term id for the interaction type that occurs between the two proteins. See http://www.ebi.ac.uk/ontology-lookup/ for more details. The term itself is also given in the i.type_name feature. |
|- | |- | ||
| − | | i. | + | | i.type_name||String||direct interaction||PSI-MI controlled vocabulary term id for the interaction type that occurs between the two proteins. See http://www.ebi.ac.uk/ontology-lookup/ for more details. The term itself is also given in the i.type_name feature. |
|- | |- | ||
| − | | i. | + | | i.query||String||NP_996224||The user's query that is responsible for returning this edge. |
|- | |- | ||
| − | | i. | + | | i.rig||Integer||27799||Redundant interaction group identifier for the interaction. This is an integer equivalent of the i.rigid. Every rig has one corresponding rigid. |
|- | |- | ||
| − | | i. | + | | i.rigid||String||TAabV6yJ1XzUvEhYwZLpu5reBU0||Redundant interaction group identifier for the interaction. This is a universal key generated for the interaction by asciibetically ordering and concatentating the rogids participating in the interaction and then generating a Base-64 representation of an SHA-1 digest of the resulting string. See PMID 18823568 for details on how this key can be generated. |
|- | |- | ||
| − | | i. | + | | i.score_hpr||Integer||15||The hpr score (highest pmid re-use) is the highest number of interactions that any one PMID (supporting this interaction) is used to support. See PMID 18823568 for details. See also score_np and score_lpr. |
|- | |- | ||
| − | | i. | + | | i.score_lpr||Integer||11||The lpr score (lowest pmid re-use) is the lowest number of distinct interactions that any one PMID (supporting this interaction) is used to support. An lpr of greater than 20 is considered to be a high-throughput experiment. See PMID 18823568 for details. See also score_np and score_lpr. |
|- | |- | ||
| − | | i. | + | | i.np||Integer||2||Number of PubMed Identifiers (PMIDs) pointing to literature where this interaction is supported. See PMID 18823568 for details. See also score_np and score_lpr. |
|- | |- | ||
| − | | i. | + | | i.source_protein||Integer||-1||TO BE DESCRIBED |
|- | |- | ||
| − | | i. | + | | i.src_intxn_db||String||grid||Original interaction database where this interaction record was obtained. |
|- | |- | ||
| − | | i. | + | | i.src_intxn_id||String||38677||Original interaction database where this interaction record was obtained. |
| + | In some case, it may be possible to right click and Search [src_intxn_id] on the web -- Interaction databases -- the database to see the original record. | ||
|- | |- | ||
| − | | i. | + | | i.target_protein||Integer||-1||TO BE DESCRIBED |
|- | |- | ||
| − | |||
|} | |} | ||
Revision as of 14:31, 25 March 2010
Date : FEB 27nd, 2010 The iRefIndex plugin for Cytoscape has not been officially released. If you are looking at this page, you have probably been directed here from the Cytoscape plugin directory at ftp://ftp.no.embnet.org/irefindex/Cytoscape/plugin . This plugin is for testing purposes only. Join the Google groups e-mail list at http://groups.google.com/group/irefindex?hl=en to be informed of the official release and updates.
Contents
- 1 Installation
- 2 Notes on platform-specific issues
- 3 Bugs
- 4 Usage
- 5 Legend
- 6 Attributes
- 7 Extra features
- 8 How to load batch query from file
- 9 Integrate user data to the plugin
- 10 Updating
- 11 Log files, search details and errors
- 12 Using the plugin as a search tool
- 13 Exit plugin and force terminate operations
- 14 Basic Operation details
Installation
Before you begin
- These instructions assume that you have downloaded and installed the Cytoscape application. See http://cytoscape.org for a manual and a set of tutorials which describe the installation and use of Cytoscape.
- Make sure Cytoscape has at least 128MB memory. See the following document for more information on setting up memory: http://cytoscape.org/cgi-bin/moin.cgi/How_to_increase_memory_for_Cytoscape
- Make sure you have an active Internet connection. During installation the plugin will download files from the iRefIndex FTP site.
- Make sure you have latest JAVA environment installed (minimum requirement Java 1.5)
- Check whether the plugin is already installed (A menu entry iRefIndex_xx under plugin menu of Cytoscape). If you want to reinstall, please uninstall previous versions. if the intention is to get the latest version use "Update plugins" from plugin menu
Using Cytoscape plugin manager

- Start Cytoscape. You must start Cytoscape as a user that has write privileges to the target directory.
- From the menu select "Plugins" -> "Manage Plugins".
To uninstall the plugin:
- Select "Currently Installed" -> "Network and Attribute I/O Plugins" and choose the iRefIndex plugin.
- Then, click the "Delete" button and confirm.
- Click "Close" to leave the "Manage Plugins" dialogue and restart Cytoscape.
To make the plugin available:

- Click on "Change Download Site" button (in the top-right-hand corner of the window).
- Click "Edit Sites".
- Click "Add" and for each of the following fields, enter the suggested values:
- Name: iRefIndex
- URL: ftp://ftp.no.embnet.org/irefindex/Cytoscape/plugin/current/plugins_irefindex.xml
- Click "OK" to close each of the dialogues until the "Manage Plugins" dialogue is visible.

To install the plugin:
- Locate "Available for Install" then "Network and Attribute I/O", verifying that iRefIndex is listed in this category.
- Select the iRefIndex plugin and then click "Install" (in the bottom-right-hand corner of the window).
- Click "Close" to leave the "Manage Plugins" dialogue.
- Go to the "Completing the installation" step below.
Manual installation
- Before starting:
- Make sure that Cytoscape is not running.
- Remove any other installations of iRefIndex beta or directories created by iRefIndex.(e.g. \.....\Cytoscape_v2.6.0\plugins\iRefIndex\ )
- Copy the iRefIndex_0.7x.jar file to the plugins directory of Cytoscape. For example:
- On Unix: /.../Cytoscape_v2.6.2/plugins/
- On Windows: \...\Cytoscape_v2.6.2\plugins\
- (You should have write privileges for this directory, during installation and also during operation.)
- You may now start Cytoscape.
Completing the installation

- We recommend that you restart Cytoscape after installing the plugin or updating it.
- First time you activate the plugin (In the main Cytoscape window, select "Plugins" -> "iRefIndex_0.7x"), you will be prompted to select an installation directory for the data and indices. The recommended place would be the plugin home directory which would appear as the recommended (default). The data and indices require a minimum disk space of 1 Gb at this location. We encourage the users to use this default directory.
- If the default directory is selected and it is not accessible the user would be prompted to restart Cytoscape. If this message appears on second or subsequent attempts, this would mean there might be a problem accessing this directory and please make sure that you have write access and a minimum available free space of 1Gb.
- The downloading and installation of indices usually takes less than 5 minutes if you have a internet connection of 10Mb/sec or more. However we have experienced delays up to 15 to 30 minutes when the installation was done using wireless network with below average signal strength. If you are planing to use the plugin in a laboratory demonstration where more than 15 people would try to perform the installation simultaneously, we recommend that everyone is not using the same wireless resource and do this in subgroups (e.g. 5 at a time). If we are informed of demonstrations we could give you advice on how to perform the installation smoothly.
- The installation process should now complete itself.
- If the installation was successful, you will see a list of indices in the Results text box in green text and if the installation fails you will see errors in red text. (If you cannot see the iRefIndex panel, click on the title "iRefIndex", near the "Network" tab of Cytoscape.)
Details of iRefindex plugin installation
- The plugin has two componants.
- The java executable file (JAR) which is the software component dealing with all the functionalities.
- Data component containing protein-protein interaction data.
both these components are required for the functioning of the plugin. The installation section above explains how to install the JAR and once the JAR is installed and the plugin is loaded the data component will be downloaded by it. The downloaded file is a compressed one and has the extension .irfz and a size around 200 MB. After the download is complete this file will be partially uncompressed (The indices and few other files required for the immediate operation will be extracted from the complex file). However, the bulk of the data will remain compressed and will be uncompressed when needed. Thus, the speed of query execution will increase with usage and the size of the iRefIndex folder will increase. Therefore, although available free space of 250Mb is enough during installation, the plugin requires available free space of 1Gb for its operation.
If the plugin manager is used for the instalation,(as of Cytoscape 2.6.3) the plugin will be placed in a directory under the home area and a record is file kept in a file named 'track_plugins.xml'. The location of these would as follows.
- Linux : ~/.cytoscape/2.6
- Windows:
The entry corresponding to iRefIndex plugin would looks like follows:
<plugin>
<uniqueID />
<name>iRefIndex</name>
<description>.<br>http://irefindex.uio.no/wiki/README_Cytoscape_plugin_0.7x<p></description>
<cytoscapeVersion>2.6</cytoscapeVersion>
<url />
<downloadUrl />
<category>Network and Attribute I/O</category>
<releaseDate>JANUARY 15, 2009</releaseDate>
<pluginVersion>0.63</pluginVersion>
<classname>cytoscape.no.uio.biotek.Main</classname>
<projectUrl>http://irefindex.uio.no</projectUrl>
<filetype>jar</filetype>
<installLocation>/............/Cytoscape_2_6_3/plugins/iRefIndex_beta6.jar</installLocation>
<license>
<text />
</license>
<authorlist>
<author>
<name>Ian Donaldson and Sabry Razick</name>
<institution>Biotechnology Centre of Oslo, University of Oslo</institution>
</author>
</authorlist>
<filelist>
<file>/........../Cytoscape_2_6_3/plugins/iRefIndex_beta6.jar</file>
</filelist>
</plugin>
- TIP!. If you do encounter an exception during start up of Cytoscape due to a plugin and there is no way of uninstalling it, you could remove the entry for the corresponding plugin from this file when Cytoscape is not running (Take a backup of the file, then delete everything from <plugin> to </plugin> for the troubling plugin, save the file and then start Cytoscape)
The downloading and installation of the plugin JAR is manged by Cytoscape core and if the plugin complies with the requirements the instalation should be smooth. However, some of our users do encounter problems when instating the data component. This is mainly due to privileged and security issues.
- Privileged issue is whether the user has access to the place where he intends to download the data component (The directory should have write access)
- Security issues are mainly encountered in Microsoft Windows based systems. When a software try to perform a suspicious operation the operation is blocked and the user is prompted confirm that this is something he knows. The the user select block in such a warning window during the installation of iRefIndex plugin, the installation fails may not be possible to install again until the block is removed manually. We have tested with several popular virus guards but have not encountered any issues relating to them yet, if you encounter any issue please report to us.
The behavior of the plugin when installed using plugin manager is different before and ofter Cytoscape is restarted. After the installation the plugin will appear in the plugin manager and could be activated, however it is not aware of its surrounding. i.e it doesn't know its installation location. Therefore it is highly recommended that the user restart Cytoscape immediately after installing the plugin and avoid activating the plugin before the first restart (do not click on the menu entry iRefIndex). When a manual installation was performed the plugin could be activated for the first start up of Cytoscape as Cytoscape is not running while the installation. After the first restart of Cytoscape after installing the plugin when the plugin is activated it tries to download the data component. For this the plugin requests a location to place the data and it suggests a default location under the home area (or plugin folder for manual installation), we recommend using this default location unless there is a absolute requirement to do otherwise.
some of the reasons behind distributing the data with the plugin rather than more popular approach like web services is as follows;
- Execution speed
- No need for a fast internet connection after installation
- Our server-side limits
- Privacy for the user (There is no monitoring of the types of searches the end user performs, this remains private unless the user decides to share it)
Notes on platform-specific issues
Windows Vista and Windows XP
You will require write privileges to the installation directory not only during installation but also during operation. If the plugin disappears from the plugin menu or it does not appear at all, then Cytoscape has to be started as an administrator. This could be done by right-clicking on Cytoscape shortcut and selecting "Run as" option. When requesting help for such situations please include a copy-paste of the Cytoscape error console ("Help" -> "Error console"). (To copy-paste, open the error console, click inside, press Ctrl-A (to select all) then Ctrl-C (to copy). The selection can then be pasted into a message using Ctrl-V.)
Mac OS X
- Please verify that Java 1.5 or later is available. The plugin will not work unless Java 1.5 or later is installed.
- Increase the Xmx setting to 512m and the Xms setting to 512m in cytoscape.sh.
- This version of the plugin is not extensively tested on Mac OS and we are sorry that the support we could provide for Mac users is limited at this point.
Unix/Linux
- Please verify that Java 1.5 or later is available.
- The "Java SE Development Kit (JDK)" from http://java.sun.com/javase/downloads/index.jsp is suitable.
- The OpenJDK packages from http://openjdk.java.net/install/ may also be suitable and are often available via distributions. For example, OpenJDK 6 for Debian and Ubuntu.
- You will require write privileges to the installation directory not only during installation but also during operation.
- The plugin behavior is proven to be very stable in Unix/Linux environments.
- To improve font appearance, try adding the following environment variable definition to your configuration (in .bashrc or .bash_profile), as described in this guide to Java fonts for Arch Linux:
export _JAVA_OPTIONS='-Dawt.useSystemAAFontSettings=lcd'
Other
If you try to install the plugin on different platforms please share your experience with us through the Google group (http://groups.google.com/group/irefindex?hl=en)
Bugs
- When updating data on Microsoft Windows XP and Vista. "Failed to find resources message" may appear in the log message window. If this happens please run the update again and the plugin will check and correct the problem during the second attempt.
Please report us if you encounter any new bug
Usage
Search for interactions involving “QCR2_HUMAN”
Using the Wizard
Click the "Wizard" button - you will get a pop-up window when you do this. The following tasks should be performed for the steps defined within the wizard dialogue:
- Select "Search protein-protein interactions for a protein".
- Select "Protein or gene name".
- For "Taxonomy identifier", select "9606 (Human)" to restrict the search to human proteins and click "Next". (Select "Any" to get results for all species.) You could also type in an NCBI taxonomy identifier into this box (http://www.ncbi.nlm.nih.gov/Taxonomy/Browser/wwwtax.cgi).
- Type QCR2_HUMAN in the provided space. Click "Next".
- Click "Perform search".
The images below show each of the steps in the wizard.
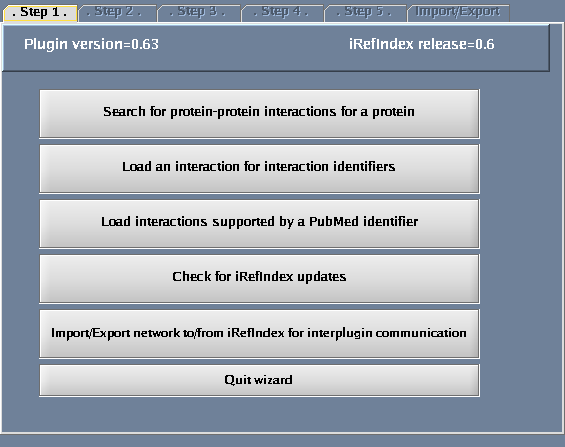
The iRefIndex wizard
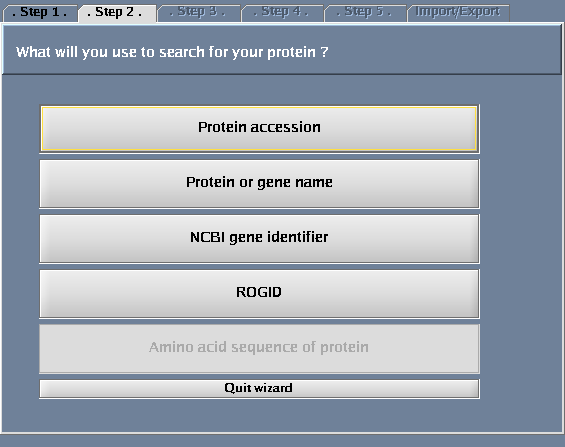
Choosing a result type
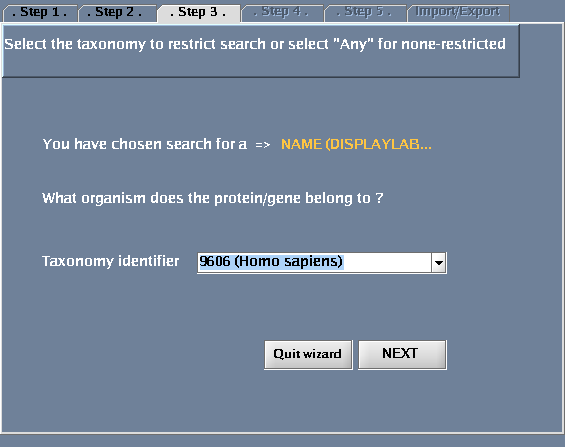
Choosing a taxonomy type
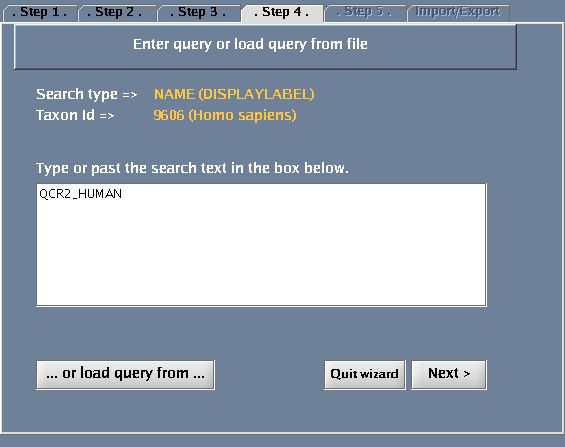
Specifying the search term
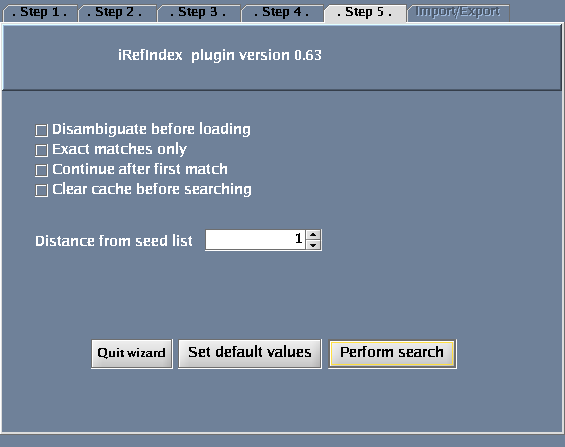
Additional options





Optional Controls
- You could specify “Distance from seed list” .
- Distance = 0: interactions between proteins in a list of proteins that you specify (this is only meaningful if you search for more than one protein in a search).
- Distance = 1: returns proteins that interact directly with a query protein(s) that you specify. This is the default choice.
- Distance = 2: returns proteins that interact directly with your query protein(s) plus their direct interactors.
Interpreting the Results
- The blue node corresponds to the protein found by your query.
- Green nodes are interacting partners for your query protein.
- Purple hexagons are complex-nodes (also called pseudo-nodes). They keep partners of a complex together (i.e. QCR6_HUMAN is found in two complexes also involving “QCR2_HUMAN”).
- Orange-yellow edges indicate protein-protein interactions and pink edges represent membership of some protein in a complex.
Some example result displays are shown below.
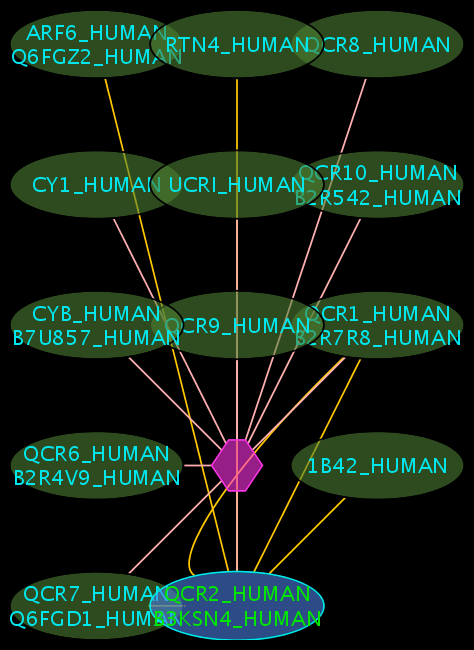
Results
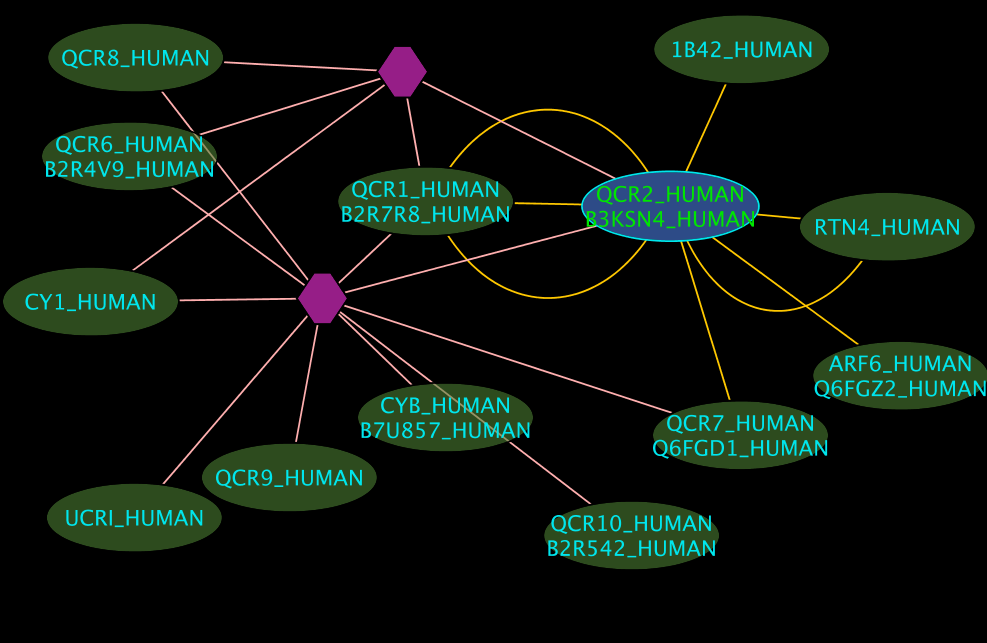
Results (tidied)


Search for interactions for a list of protein accessions
- Creating a batch file
- Using the Wizard
- Using Advanced mode
Legend

Attributes

{kind=link}
There are two types of attributes available from iRefIndex. Some of this are directly s useful for to the user as the 'i.name' which provides the name of the protein. Some others, are intended to be used for filters i.e. 'i.order'. Brief description of each one of these are given below.
- To display attributes the user have to select the ones to be displayed.
- This could be done by clicking ion the select attribute button and ticking the attributes to be displayed. (This button is located in the data panel). Please see the image on the right, the red arrow points to "Select attribute"
Node Attributes
Each node represents a distinct amino acid sequence (protein) from a distinct organism (taxon id). Each of the attributes below, provide additional information about the node. Although each node is distinct, a graph produced by iRefIndex may contain multiple nodes that are related proteins (i.e., splice isoform products from the same gene). These nodes will all have the same "i.canonical_rog" and i.canonical_rogid" feature values. See notes below.
Node attributes that can be lists of items (like i.UniProt) will have a corresponding attribute called i.[attribute name]_TOP (e.g. i.UniProt_TOP) that is the first item of the list.
| Attribute name | Data type | Example value | Description |
|---|---|---|---|
| ID | Integer | 10121899 | This is a unique identifier for the node assigned by iRefIndex (no two nodes will have the same ID). Each node corresponds to distinct amino acid sequence from a distinct taxon id. See also i.rog and i.rogid |
| canonicalName | Integer | 10121899 | This is the same as ID. This attribute is set by Cytoscape and is unrelated to the i.canonical_rog or i.canonical_rogid used by iRefIndex |
| i.RefSeq_Ac | List | [NP_996224] | All RefSeq accessions with an amino acid sequence and taxon identifier identical to the protein represented by this node. Right click on this entry and select "Search [RefSeq_Ac] on the web -- Entrez -- Protein" for more information. See also i.RefSeq_TOP for the first entry in this list of accessions. |
| i.UniProt_Ac | List | [Q7KSF4] | All UniProt accessions with an amino acid sequence and taxon identifier identical to the protein represented by this node. Right click on this entry and select "Search [UniProt_Ac] on the web -- UniProt -- KB Beta" for more information. See also i.UniProt_Ac_TOP for the first entry in this list of accessions. |
| i.UniProt_ID | List | [Q7KSF4_DROME] | All UniProt IDs with an amino acid sequence and taxon identifier identical to the protein represented by this node. Right click on this entry and select "Search [UniProt_ID] on the web -- UniProt -- KB Beta" for more information. See also i.UniProt_ID_TOP for the first entry in this list of IDs. |
| i.canonical_rog | Integer | 10121899 | Related proteins (say splice isoforms from the same gene) will all belong to the same canonical group. One member of this group is assigned as the canonical representative of this group. The i.canonical_rog attribute lists the identifier of the protein's canonical group identifier. For example, all products of Entrez Gene 42066 have the same i.canonical_rog (10121899). Each of these gene products has its own identifier (because they each have a distinct amino acid sequence). One of the splice isoforms (NP_996224) was chosen as the canonical representative of this group. See http://irefindex.uio.no/wiki/Canonicalization for more details on how canonical groups are constructed and how canonical representatives are chosen. |
| i.canonical_rogid | String | 1ZFb1WlW0OgOlhiAPtkJTdb6oOg7227 | This is a unique alphanumeric key for the canonical representative of the canonical group to which this node belongs. Briefly, an SHA-1 digest of the amino acid sequence is used to generate a unique 27 character key and this is pre-pended to the taxon id for the protein's source organism in order to make the rogid. See PMID 18823568 for details on how this key can be generated. This is a string equivalent of the i.canonical_rog attribute. All canonical_rog's (an integer) have one corresponding canonical_rogid. See http://irefindex.uio.no/wiki/Canonicalization for more details on how canonical groups are constructed and how canonical representatives are chosen. Note that the rogid for the protein represented by this specific node is listed under i.rogid. |
| i.dataset | Integer | 0 | TO BE DESCRIBED |
| i.displayLabel | List | [Q7KSF4_DROME] | This is a list of short labels chosen by iRefIndex to label the node using the VizMapper. The UniProt ID is preferentially chosen (if one is available) followed by the Entrez Gene Symbol. See also i.displayLabel_TOP for the first entry in this list. |
| i.geneID | List | [42066] | All NCBI Entrez Gene Identifiers that encode a protein sequence identical to that of this node. Right click on this entry and select "Search [geneID] on the web -- Entrez -- Gene" for more information. See also i.geneID_TOP for the first entry in this list. |
| i.geneSymbol | List | [CHER] | All NCBI Entrez Gene Official Sybols that encode a protein sequence identical to that of this node. Right click on this entry and select "Search [geneSymbol] on the web -- Entrez -- Gene" for more information. See also i.geneSymbol_TOP for the first entry in this list. |
| i.interactor_description | List | [Q7KSF4_DROME, CHER, DMEL_CG3937, SKO, DMEL CG3937, FLN, CG3937, CHER, DMEL\\CG3937, FLN, SKO, CHER, NAME=CHER, DMEL_CG3937] | A collection of all the names in their short form as given by the original interaction databases. See also i.interactor_description_TOP for the first entry in this list. |
| i.mw | Integer | 259142 | Molecular weight associated with the protein sequence for this node. From UniProt if available. You can search for nodes inside a MW range using the "mw" search type in the iRefIndex plugin. |
| i.order | Integer | 0 | TO BE DESCRIBED. The distance of this node from the query node (query node = 0 , direct neighbors = 1 ). Pseudonodes have negative values (-1 = complex holder, -2 = collapsed instance ) |
| i.overall_degree | Integer | 42 | The total number of interactions described for this node in the iRefIndex database. Not all of these edges will be necessarily shown in the current view. |
| i.popularity | List | 42 | TO BE DESCRIBED |
| i.pseudonode | Boolean | false | This is set to true is the node represents a "complex" or n-ary interaction record. Protein nodes with edges incident to a pseudonode are member interactors from the interaction record where specific interactions between pairs of interactors is unknown. Pseudonodes appear as hexagons when using the iRefIndex VizMapper style. |
| i.query | String | NP_996224 | The user query used to retrieve this specific node. Neighbours of "query" nodes will not have an i.query value. Nodes returned by queries are coloured blue when using the iRefIndex VizMapper style. |
| i.rog | Integer | 10121899 | This is a unique identifier for the node assigned by iRefIndex (no two nodes will have the same ID). Each node corresponds to distinct amino acid sequence from a distinct taxon id. i.rog also appears as the ID attribute. Each i.rog has a corresponding i.rogid - see below. |
| i.rogid | String | 2mL9oLZ9g/SSPyK0nOz97RmOzPg3702 | This is a unique alphanumeric key for the protein represented by this node. Briefly, an SHA-1 digest of the amino acid sequence is used to generate a unique 27 character key and this is pre-pended to the taxon id for the protein's source organism in order to make the rogid. See PMID 18823568 for details on how this key can be generated. This is a string equivalent of the i.rog attribute. All i.rog's (an integer) have one corresponding i.rogid. |
| i.taxid | Integer | 7227 | The NCBI taxonomy identifier for this protein's source organism. See http://www.ncbi.nlm.nih.gov/taxonomy?term=7227 for more details. |
| i.xref | List | [AAF70826.1,Q9M6R5] | All the accessions as given by the original interaction database records to describe this protein. See also i.xref_TOP for the first entry in this list. |
Edge Attributes
Each edge represents a distinct primary database record that supports some relationship between the two incident nodes. So, if an interaction between two proteins has been annotated by two databases (or twice by the same database) then two edges will appear between those two protein nodes.
| Attribute name | Data type | Example value | Description |
|---|---|---|---|
| ID | String | 10121899 (2771704(40952)) 13911416 | This is a unique identifier for the edge assigned by Cytoscape (no two edges would have same ID). See i.rig and i.rigid for unique identifiers for the edge assigned by iRefIndex. |
| I.PMID | Integer | 14605208 | Publication identifier of the publication where the interaction represented by the edge mentioned. Right click on this entry and select: Search [PMID] on the web -- Entrez -- Pubmed for more details on the publication. |
| i.bait | Integer | 13911416 | Node ID for the protein that was used as a bait in this experiment. Only applicable where the experimental system (see i.method_name) used to support this relationship was a bait-prey system (e.g. two hybrid). |
| i.canonical_rig | Integer | 27799 | See notes for i.rig edge feature. This is the rig constructed for the interaction using its canonical rogs. Use a web browser to query http://wodaklab.org/iRefWeb/interaction/show/27799 (where 27799 is the canonical_rig) to retrieve more information on this interaction and equivalent source interaction records. |
| i.experiment | String | Giot L [2003] | A short label for the experiment where this interaction was found (usually contains authors names). |
| i.flag | Integer | 1 | Used by iRefIndex plugin to control display of edges (0- the representative edge, used in edge toggle, 1- an edge which will disappear during edge toggle, 2- complex holder edge,6-a path, 7-Edge from or to a collapsed node). |
| i.host_taxid | Integer | 7227 | Indicates the organism taxon id where the interaction was experimentally demonstrated. |
| i.isLoop | Integer | 1 | Indicates whether the interaction is a self interaction (i.e dimer or possibly multimer of the same protein type). See the source interaction record for details. |
| i.method_cv | String | MI:0018 | PSI-MI controlled vocabulary term id for the method used to provide evidence for this interaction. See http://www.ebi.ac.uk/ontology-lookup/ for more details. The name of the method is also given in the i.method_name feature. |
| i.method_name | String | two hybrid | PSI-MI controlled vocabulary term name for the method used to provide evidence for this interaction. See http://www.ebi.ac.uk/ontology-lookup/ for more details. The term identifer is also given in the i.method_cv feature. |
| i.participant_identification | String | predetermined participant | PSI-MI controlled vocabulary term for the participant identification method used to provide evidence for this interaction. See http://www.ebi.ac.uk/ontology-lookup/ for more details. The identifier for the term is also given in the i.participant_cv feature. |
| i.participant_cv | String | predetermined participant | PSI-MI controlled vocabulary term id for the participant identification method used to provide evidence for this interaction. See http://www.ebi.ac.uk/ontology-lookup/ for more details. The term itself is also given in the i.participant_identification feature. |
| i.type_cv | String | MI:0407 | PSI-MI controlled vocabulary term id for the interaction type that occurs between the two proteins. See http://www.ebi.ac.uk/ontology-lookup/ for more details. The term itself is also given in the i.type_name feature. |
| i.type_name | String | direct interaction | PSI-MI controlled vocabulary term id for the interaction type that occurs between the two proteins. See http://www.ebi.ac.uk/ontology-lookup/ for more details. The term itself is also given in the i.type_name feature. |
| i.query | String | NP_996224 | The user's query that is responsible for returning this edge. |
| i.rig | Integer | 27799 | Redundant interaction group identifier for the interaction. This is an integer equivalent of the i.rigid. Every rig has one corresponding rigid. |
| i.rigid | String | TAabV6yJ1XzUvEhYwZLpu5reBU0 | Redundant interaction group identifier for the interaction. This is a universal key generated for the interaction by asciibetically ordering and concatentating the rogids participating in the interaction and then generating a Base-64 representation of an SHA-1 digest of the resulting string. See PMID 18823568 for details on how this key can be generated. |
| i.score_hpr | Integer | 15 | The hpr score (highest pmid re-use) is the highest number of interactions that any one PMID (supporting this interaction) is used to support. See PMID 18823568 for details. See also score_np and score_lpr. |
| i.score_lpr | Integer | 11 | The lpr score (lowest pmid re-use) is the lowest number of distinct interactions that any one PMID (supporting this interaction) is used to support. An lpr of greater than 20 is considered to be a high-throughput experiment. See PMID 18823568 for details. See also score_np and score_lpr. |
| i.np | Integer | 2 | Number of PubMed Identifiers (PMIDs) pointing to literature where this interaction is supported. See PMID 18823568 for details. See also score_np and score_lpr. |
| i.source_protein | Integer | -1 | TO BE DESCRIBED |
| i.src_intxn_db | String | grid | Original interaction database where this interaction record was obtained. |
| i.src_intxn_id | String | 38677 | Original interaction database where this interaction record was obtained.
In some case, it may be possible to right click and Search [src_intxn_id] on the web -- Interaction databases -- the database to see the original record. |
| i.target_protein | Integer | -1 | TO BE DESCRIBED |
Extra features
To be described
- Edge Toggle
- Load user variables
How to load batch query from file
1. Create a text file with the following format:
<type><NCBI_taxonomy_identifier>
query_text_1
query_text_2
query_text_3
The first line of the file starts with a hash ("#") and then the type. The type could be
- ACCESSION
- NAME
- GENID
The query_text is your query (e.g.Q39009). Each query line has to be terminated by a new line character (press enter after each line)
[Sample batch file: [1]]
Integrate user data to the plugin
How to create your own file to use as index
How to create node and edge attributes
Example: Attaching disease group identifiers to Nodes (http://irefindex.uio.no/wiki/DiG:_Disease_groups)
Updating
- From Cytoscape updater
- Using plugins update feature
Log files, search details and errors
- How to interpret log messages and save them for later reference.
Using the plugin as a search tool
The plugin could also be used to search the current network. However, there is a better search option in Cytoscape with Google suggest which may be more convenient to use. The reason for including the search function was that the Cytoscape search filed remained inactive on some occasions for networks crated using the plugin. The reason for this is still unknown and deleting a node on the network seems to activate it, when this bug will be fixed the users are encouraged to use the Cytoscape search option. Currently, if a user performs a search with a term and if the corresponding protein is already loaded, the loaded protein (corresponding node) would be highlighted with Cytoscape default highlight colors.
Exit plugin and force terminate operations
The exit button performs two functions.
- First one is to exit iRefIndex plugin, where the outcome is to detach the plugin from Cytoscape.
- The second function "FORCE STOP" (only available during a active task) is to terminate current operation. The "FORCE STOP" is useful when the search query or a subsequent operation takes too long to finish or none-responding. When a force stop is performed the out come is unpredictable and behavior was undefined, therefore results after such operation could not be trusted.
Basic Operation details
During installation the plugin downloads protein-protein interaction data from iRefIndex (ftp://ftp.no.embnet.org/irefindex/Cytoscape/plugin/current/) in a compressed form. The downloaded files will be in the directory iRefIndex under the Cytoscape plugin folder. We recommend not to change any files in this folder as this may lead to unpredictable results. Especially, please do not open them in word processor software (e.g. Microsoft office). After successful installation you will also find some index files and serialized Java objects files which will be used in search and load operations.
- Brief description of the files
- irft files: this file contains a ROG(Redundant Object Group) to PARAMETER mapping. This is a sort of index that maps identifiers like accessions and names to ROGs. The ROG is an integer representation of the ROGID. However, ROG is not stable like ROGID and it may be different from one version to another. However, from beta4 onwards the ROGID to ROG mapping will be propagated for backwards compatibility for live proteins (proteins which are not removed from original source).
- Irfm files: These are index files containing information about partners of each interaction.
- ROGS Directory: Contains protein attributes (Warning! Please do not try to open this directory in a file browser; the computer may crash)
- RIGS Directory: Contains interaction attributes (Warning! Please do not try to open this directory in a file browser; the computer may crash)
- Irfj files : these files contain the interaction and object data in a compressed form. When requested for the first time the information will be uncompressed to the RIGS or ROGS directory.