Difference between revisions of "iRefScape 0.9"
(O) |
PaulBoddie (talk | contribs) (Updated links.) |
||
| (5 intermediate revisions by 3 users not shown) | |||
| Line 1: | Line 1: | ||
| − | + | Last edited: {{REVISIONYEAR}}-{{padleft:{{REVISIONMONTH}}|2}}-{{REVISIONDAY2}} | |
| − | |||
| − | + | Release date: June 23rd, 2010 | |
| − | + | This page describes the iRefScape 0.9 plug-in for Cytoscape 2.7.0. See the following table for more detailed iRefScape compatibility information. | |
| − | + | {| border="1" cellspacing="0" cellpadding="5" style="margin: 2em" | |
| − | As the 2.7.0 VisualMappingManager is not backward compatible with 2.6.3 please do not | + | ! align="center" style="background:#f0f0f0;"|Cytoscape |
| − | use this version with Cytoscape 2.6.3. | + | ! align="center" style="background:#f0f0f0;"|iRefScape |
| − | + | ! align="center" style="background:#f0f0f0;"|Remarks | |
| − | + | |- | |
| + | | 2.7.0 | ||
| + | | iRefScape 0.9 (described on this page) | ||
| + | | As the 2.7.0 VisualMappingManager is not backward compatible with 2.6.3, please do not use this version with Cytoscape 2.6.3. | ||
| + | |- | ||
| + | | 2.6.3 | ||
| + | | [[iRefScape 0.8]] | ||
| + | | | ||
| + | |} | ||
| − | + | Join the [http://groups.google.com/group/irefindex?hl=en iRefIndex Google Group] to be informed of updates. See also the [[iRefScape|latest release of iRefScape]] which may differ from the release described here. | |
==Installation== | ==Installation== | ||
| Line 20: | Line 27: | ||
Follow the on-screen instructions. | Follow the on-screen instructions. | ||
| − | More detailed instructions, troubleshooting tips and alternative methods are available on the [ | + | More detailed instructions, troubleshooting tips and alternative methods are available on the [[iRefScape 0.8 Installation]] page and this can be followed for iRefScape 0.9 as well. |
After, installation, select the entry of the form "iRefScape_0.9x" from Cytoscape's plugin menu. | After, installation, select the entry of the form "iRefScape_0.9x" from Cytoscape's plugin menu. | ||
| Line 143: | Line 150: | ||
=== iRefScape Menu === | === iRefScape Menu === | ||
| − | The iRefScape menu in the | + | The iRefScape menu in the Cytoscape menu bar contains a number of other functions that may help with searching and viewing interaction data. These are described in more detail on the [[iRefScape plugin menu]] page. |
=== Expanding the Interaction Map === | === Expanding the Interaction Map === | ||
| Line 299: | Line 306: | ||
|- | |- | ||
|} | |} | ||
| + | |||
| + | === User Attributes === | ||
| + | Importing - TBD | ||
| + | |||
| + | Searching on - TBD | ||
==Obtaining CORUM, DIP and HPRD Data== | ==Obtaining CORUM, DIP and HPRD Data== | ||
| Line 433: | Line 445: | ||
Groups are separated by a pipe ("|"). | Groups are separated by a pipe ("|"). | ||
| − | Q&A fore list comparison | + | ====Q&A fore list comparison==== |
| − | Q. What is the maximum number of members a group can have ? | + | *Q. What is the maximum number of members a group can have ? |
| − | A. You could have any number of members, more members there are more time it will take for the operation and more memory it will need. Fro instance the above example search will complete comfortably in 1 minute with 256Mb of allocated memory. If you have more than 100 members we recommend having at least 1Gb dedicated memory for Cytoscape. | + | *A. You could have any number of members, more members there are more time it will take for the operation and more memory it will need. Fro instance the above example search will complete comfortably in 1 minute with 256Mb of allocated memory. If you have more than 100 members we recommend having at least 1Gb dedicated memory for Cytoscape. |
| − | Q. Can I compare more than two groups. | + | *Q. Can I compare more than two groups. |
| − | A Yes , each group should be separated with a pipe character. Maximum number of recommended group count is 255. | + | *A Yes , each group should be separated with a pipe character. Maximum number of recommended group count is 255. |
| − | Q What if a protein or protein resulting from query appears in more than one group ? | + | *Q What if a protein or protein resulting from query appears in more than one group ? |
| − | All proteins found in more than one group is treated as a new group. | + | *A All proteins found in more than one group is treated as a new group. |
| − | Q. Can I compare members of already grouped identifier ? | + | *Q. Can I compare members of already grouped identifier ? |
| − | A. Yes. As an example if you want to compare interactions among the disease group 141, the following query could be used. | + | *A. Yes. As an example if you want to compare interactions among the disease group 141, the following query could be used. |
COMPARE{141} | COMPARE{141} | ||
Latest revision as of 16:13, 6 July 2011
Last edited: 2011-07-06
Release date: June 23rd, 2010
This page describes the iRefScape 0.9 plug-in for Cytoscape 2.7.0. See the following table for more detailed iRefScape compatibility information.
| Cytoscape | iRefScape | Remarks |
|---|---|---|
| 2.7.0 | iRefScape 0.9 (described on this page) | As the 2.7.0 VisualMappingManager is not backward compatible with 2.6.3, please do not use this version with Cytoscape 2.6.3. |
| 2.6.3 | iRefScape 0.8 |
Join the iRefIndex Google Group to be informed of updates. See also the latest release of iRefScape which may differ from the release described here.
Contents
Installation
The plugin can be installed using Cytoscape's plugin menu. Select "Manage plugins" and then "Available for Install" and then "Network and Attribute I/O" and finally "iRefScape v.0.9x" (where the precise version will use only digits, such as "iRefScape v.0.90").
Follow the on-screen instructions.
More detailed instructions, troubleshooting tips and alternative methods are available on the iRefScape 0.8 Installation page and this can be followed for iRefScape 0.9 as well.
After, installation, select the entry of the form "iRefScape_0.9x" from Cytoscape's plugin menu.
When the plugin is started for the first time, it will download the publicly available data set.
Using the Wizard - an example search
Click the "Wizard" button - a pop-up window will appear.
Follow these steps
- Select "Search protein-protein interactions for a protein".
- Select "UniProt identifier".
- For "Taxonomy identifier", select "9606 (Human)"
- Type QCR2_HUMAN in the provided space. Click "Next".
- Click "Search & load".
The images below show each of the steps in the wizard.
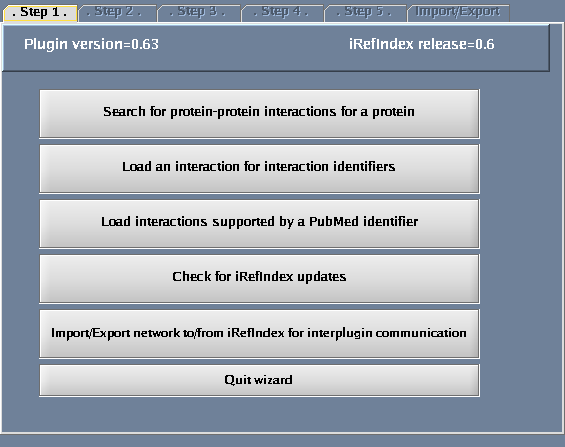
The iRefIndex wizard
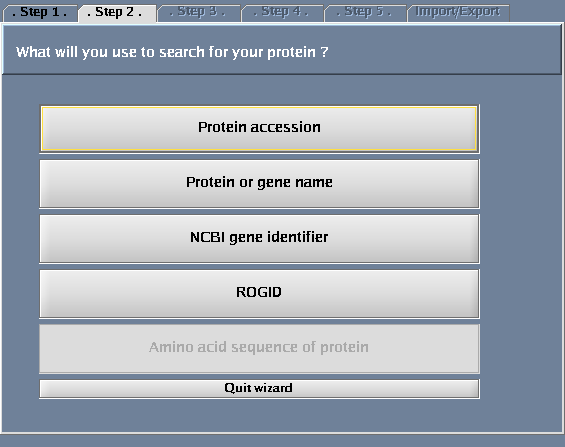
Choosing a result type
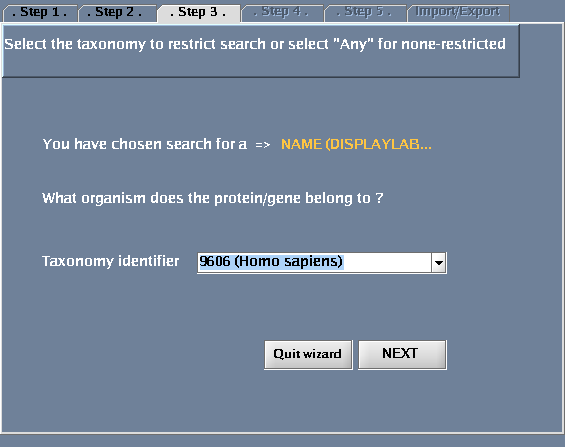
Choosing a taxonomy type
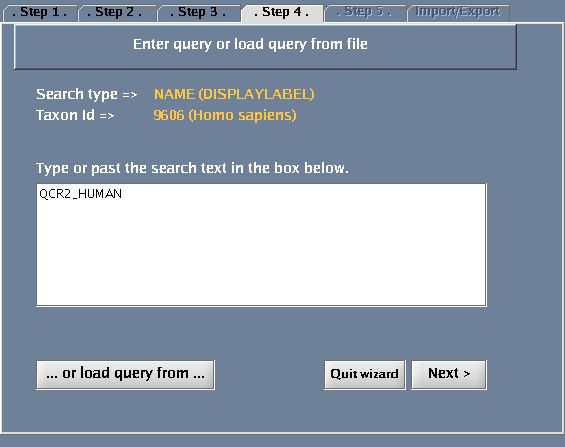
Specifying the search term
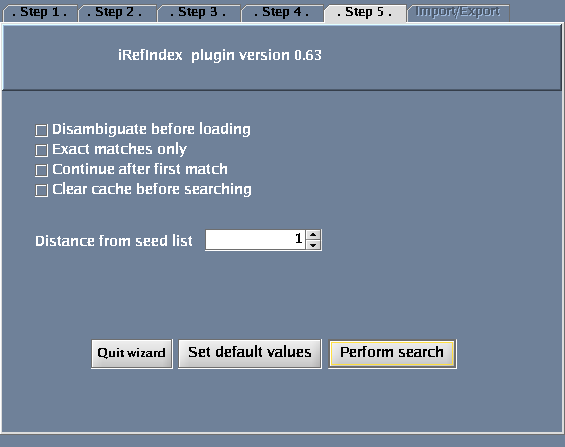
Additional options





Using the Search Panel
To perform a search, the following steps are involved:
- Enter query term(s)
- Select a search type
- Select taxonomy/organism
- Adjust search options (iterations, new view, canonical expansion) - this is optional
- Start the search
Enter query term(s)
Queries may be loaded from a file or by pasting the query into the text box (one query per line). Multiple queries can also be separated by pipe characters (|) or by tab characters. Queries with spaces in them should be enclosed in double quotes.
Select a search type
Example searches are listed below.
| Search Type | Example | Notes |
|---|---|---|
| RefSeq_Ac | NP_996224 | See http://www.ncbi.nlm.nih.gov/protein/221379660 |
| UniProt_Ac | Q7KSF4 | See http://www.uniprot.org/uniprot/Q7KSF4 |
| UniProt_ID | Q7KSF4_DROME | See http://www.uniprot.org/uniprot/Q7KSF4 |
| geneID | 42066 | See http://www.ncbi.nlm.nih.gov/sites/entrez?db=gene&cmd=Retrieve&dopt=full_report&list_uids=42066 |
| geneSymbol | cher | See http://www.ncbi.nlm.nih.gov/sites/entrez?db=gene&cmd=Retrieve&dopt=full_report&list_uids=42066 |
| mass | 72854<-->72866 | Search protein interactors for a range of molecular mass (in Da). |
| rog | 10121899 | Redundant object group: iRefIndex's internal identifier for a protein |
| PMID | 14605208 | PubMed Identifier where an interaction is described. See http://www.ncbi.nlm.nih.gov/pubmed. Iterations and "Use canonical expansion" have no effect on this search type. This search will return all protein interactors in the given PMID and will automatically draw all interactions known between these proteins (even if these interactions are supported by different PMIDs). Select edges in the resulting graph, and see the i.PMID attribute in the Edge Attribute Browser. |
| src_intxn_id | EBI-212627 | Source interaction database identifier. Iterations and "Use canonical expansion" have no effect on this search type. Caution: multiple databases may have overlapping interaction record identifiers (e.g. 147805 returns records from both BIND and BioGrid) and there is no way to limit this search to a specific database at this time.
Equivalent interactions from other databases will be automatically retrieved using this search type (see provided example). |
| omim | 227650 | OMIM identifier. See http://www.ncbi.nlm.nih.gov/entrez/dispomim.cgi?id=227650 |
| digid | 449 | Internal identifier for a group of phenotypically related diseases. See http://donaldson.uio.no/wiki/DiG:_Disease_groups. A digid can be found by first performing a search for some omim identifier - the digid will then appear as the i.digid node attribute. |
Select taxonomy/organism
This will limit the search results to a particular organism. An organism can be selected from the list, or a taxonomy identifier can be entered into the field itself. See Entrez Taxonomy for more details on taxonomy identifiers. For most search types, it is acceptable to leave this field set to Any.
Adjust search options
The following optional adjustments can be made:
Iterations
A distance from the query list's members can be specified:
- Selecting 0 will return only interactions between nodes found by the query list
- Selecting 1 will return immediate neighbours of nodes in the query list
Create new view
A new view will be opened for the search results if this option is selected. Otherwise, the results will be added to the current view.
Use canonical expansion
Selecting this option will expand the search to include all proteins that are related to the query protein (for example, splice isoforms). See Canonicalization for technical details.
Start the search
Press the "Search and load" button to perform the search.
Viewing the Results
Colours and Shapes
- Blue nodes corresponds to proteins found by your query
- Green nodes are interacting partners for your query protein
- Purple hexagons are complex-nodes (also called pseudo-nodes); they keep partners of a complex together (i.e. QCR6_HUMAN is found in two complexes also involving "QCR2_HUMAN")
- Orange-yellow edges indicate protein-protein interactions and pink edges represent membership of some protein in a complex
Toggling Edges
Multiple edges may appear between two nodes. These represent separate interaction records that support this link. Details on each original record can be viewed using the edge attribute viewer (below). You can toggle this multi-view on and off by selecting "Toggle selected multi-edges" in the iRefScape/View Tools menu. Only one of the edges will be shown in the collapsed view.
iRefScape Menu
The iRefScape menu in the Cytoscape menu bar contains a number of other functions that may help with searching and viewing interaction data. These are described in more detail on the iRefScape plugin menu page.
Expanding the Interaction Map
You can search for additional interactions by right-clicking on a node and selecting "iRefIndex -- Retrieve interactions".
Some example result displays are shown below.
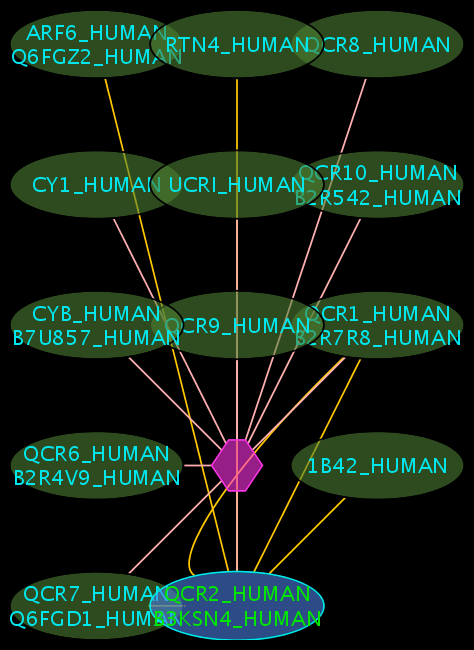
Results
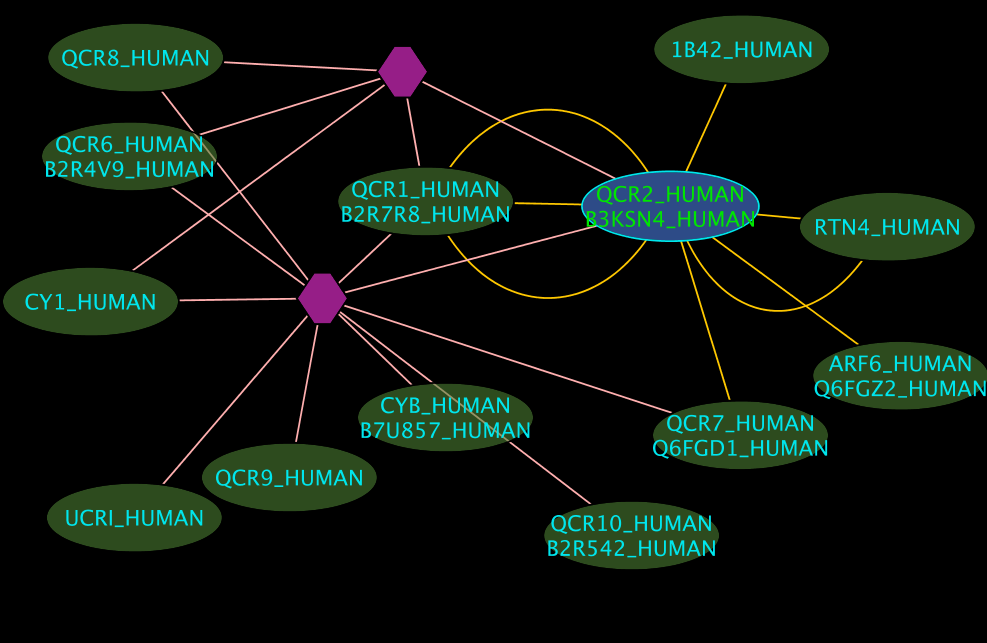
Results (tidied)


Attributes

There are two types of attributes available from iRefIndex: node attributes and edge attributes. These may be used to view information about selected nodes or edges (like i.taxid). Some features may allow the user to link out to additional data sources through the "right-click" menu (like i.geneID). Features may also be used to sort and select nodes and edges with specific attributes (like i.order). The i.query feature shows the user's query that is responsible for returning the node or edge.
Brief descriptions and examples of each attribute are provided below.
The user must first select the attributes that are to be displayed. This can be done by clicking on the "attribute" icon at the top of the node or edge attribute browser, as shown in the illustrative images.
Node Attributes

Each node represents a distinct amino acid sequence (protein) from a distinct organism (taxonomy identifier). Each of the attributes below, provide additional information about the node. Although each node is distinct, a graph produced by iRefIndex may contain multiple nodes that are related proteins (such as splice isoform products from the same gene). These nodes will all have the same i.canonical_rog and i.canonical_rogid feature values. See the notes below.
Node attributes that can be lists of items (like i.UniProt) will have a corresponding attribute called i.attribute name_TOP (for example, i.UniProt_TOP) which provides the first item of the associated list.
| Attribute name | Data type | Example value | Description |
|---|---|---|---|
| ID | Integer | 10121899 | This is a unique identifier for the node assigned by iRefIndex (no two nodes will have the same ID). Each node corresponds to a distinct amino acid sequence from a distinct taxonomy identifier. See also i.rog and i.rogid. |
| canonicalName | Integer | 10121899 | This is the same as ID. This attribute is set by Cytoscape and is unrelated to the i.canonical_rog or i.canonical_rogid used by iRefIndex |
| i.RefSeq_Ac | List | [NP_996224] | All RefSeq accessions with an amino acid sequence and taxon identifier identical to the protein represented by this node. Right click on this entry and select "Search [RefSeq_Ac] on the web -- Entrez -- Protein" for more information. See also i.RefSeq_TOP for the first entry in this list of accessions. |
| i.UniProt_Ac | List | [Q7KSF4] | All UniProt accessions with an amino acid sequence and taxonomy identifier identical to the protein represented by this node. Right click on this entry and select "Search [UniProt_Ac] on the web -- UniProt -- KB Beta" for more information. See also i.UniProt_Ac_TOP for the first entry in this list of accessions. |
| i.UniProt_ID | List | [Q7KSF4_DROME] | All UniProt identifers with an amino acid sequence and taxonomy identifier identical to the protein represented by this node. Right click on this entry and select "Search [UniProt_ID] on the web -- UniProt -- KB Beta" for more information. See also i.UniProt_ID_TOP for the first entry in this list of IDs. |
| i.canonical_rog | Integer | 10121899 | Related proteins (say splice isoforms from the same gene) will all belong to the same canonical group. One member of this group is assigned as the canonical representative of this group. The i.canonical_rog attribute lists the identifier of the protein's canonical group identifier. For example, all products of Entrez Gene 42066 have the same i.canonical_rog (10121899). Each of these gene products has its own identifier (because they each have a distinct amino acid sequence). One of the splice isoforms (NP_996224) was chosen as the canonical representative of this group. See the canonicalization document for more details on how canonical groups are constructed and how canonical representatives are chosen. |
| i.canonical_rogid | String | 1ZFb1WlW0OgOlhiAPtkJTdb6oOg7227 | This is a unique alphanumeric key for the canonical representative of the canonical group to which this node belongs. Briefly, an SHA-1 digest of the amino acid sequence is used to generate a unique 27 character key and this is prepended to the taxonomy identifier for the protein's source organism in order to make the rogid. See PMID 18823568 for details on how this key can be generated. This is a string equivalent of the i.canonical_rog attribute. All i.canonical_rog instances (each being an integer) have one corresponding i.canonical_rogid. See the canonicalization document for more details on how canonical groups are constructed and how canonical representatives are chosen. Note that the rogid for the protein represented by this specific node is listed under i.rogid. |
| i.dataset | Integer | 0 | TO BE DESCRIBED |
| i.digid | List | 449 | This is an integer identifier that is shared by a group of disease entries in OMIM that are related by their titles. See the disease groups document for more details. Also see i.omim and i.dig_title. |
| i.displayLabel | List | [Q7KSF4_DROME] | This is a list of short labels chosen by iRefIndex to label the node using the VizMapper. The UniProt identifier is preferentially chosen (if one is available) followed by the Entrez Gene Symbol. See also i.displayLabel_TOP for the first entry in this list. |
| i.geneID | List | [42066] | All NCBI Entrez Gene identifiers that encode a protein sequence identical to that of this node. Right click on this entry and select "Search [geneID] on the web -- Entrez -- Gene" for more information. See also i.geneID_TOP for the first entry in this list. |
| i.geneSymbol | List | [CHER] | All NCBI Entrez Gene official symbols that encode a protein sequence identical to that of this node. Right click on this entry and select "Search [geneSymbol] on the web -- Entrez -- Gene" for more information. See also i.geneSymbol_TOP for the first entry in this list. |
| i.interactor_description | List | [Q7KSF4_DROME, CHER, DMEL_CG3937, SKO, DMEL CG3937, FLN, CG3937, CHER, DMEL\\CG3937, FLN, SKO, CHER, NAME=CHER, DMEL_CG3937] | A collection of all the names in their short form as given by the original interaction databases. See also i.interactor_description_TOP for the first entry in this list. |
| i.mass | Integer | 259142 | Mass associated with the protein sequence for this node. From UniProt, if available. You can search for nodes inside a mass range using the mass search type in the iRefIndex plugin. |
| i.omim | List | [608053] | List of OMIM disease identifiers associated with this protein. Right click on the entry and select "Search for [omim] on the web -- Entrez -- OMIM" for more information. |
| i.order | Integer | 0 | The distance of this node from the query node (query node has distance 0, nodes that are returned by a query because they are a part of the same canonical group have a value of 10, direct neighbours have a value of1). Pseudonodes have negative values (-1 is a complex holder, -2 is a collapsed instance). |
| i.overall_degree | Integer | 42 | The total number of interactions described for this node in the iRefIndex database. Not all of these edges will be necessarily shown in the current view. |
| i.popularity | List | 42 | TO BE DESCRIBED |
| i.pseudonode | Boolean | false | This is set to true is the node represents a "complex" or n-ary interaction record. Protein nodes with edges incident to a pseudonode are member interactors from the interaction record where specific interactions between pairs of interactors is unknown. Pseudonodes appear as hexagons when using the iRefIndex VizMapper style. |
| i.query | String | NP_996224 | The user query used to retrieve this specific node. Neighbours of "query" nodes will not have an i.query value. Nodes returned by queries are coloured blue when using the iRefIndex VizMapper style. |
| i.rog | Integer | 10121899 | This is a unique identifier for the node assigned by iRefIndex (no two nodes will have the same ID). Each node corresponds to a distinct amino acid sequence associated with a distinct taxonomy identifier. i.rog also appears as the ID attribute. Each i.rog has a corresponding i.rogid - see below. |
| i.rogid | String | 2mL9oLZ9g/SSPyK0nOz97RmOzPg3702 | This is a unique alphanumeric key for the protein represented by this node. Briefly, an SHA-1 digest of the amino acid sequence is used to generate a unique 27 character key and this is prepended to the taxonomy identifier for the protein's source organism in order to make the rogid. See PMID 18823568 for details on how this key can be generated. This is a string equivalent of the i.rog attribute. All i.rog instances (each being an integer) have one corresponding i.rogid. |
| i.taxid | Integer | 7227 | The NCBI taxonomy identifier for this protein's source organism. See http://www.ncbi.nlm.nih.gov/taxonomy?term=7227 for more details of this example value for i.taxid. |
| i.xref | List | [AAF70826.1,Q9M6R5] | All the accessions as given by the original interaction database records to describe this protein. See also i.xref_TOP for the first entry in this list. |
Edge Attributes
Each edge represents a distinct primary database record that supports some relationship between the two incident nodes. So, if an interaction between two proteins has been annotated by two databases (or twice by the same database) then two edges will appear between those two protein nodes.
| Attribute name | Data type | Example value | Description |
|---|---|---|---|
| ID | String | 10121899 (2771704(40952)) 13911416 | This is a unique identifier for the edge assigned by Cytoscape (no two edges will have same ID). See i.rig and i.rigid for unique identifiers for the edge assigned by iRefIndex. |
| i.PMID | Integer | 14605208 | Publication identifier of the publication where the interaction represented by the edge mentioned. Right click on this entry and select "Search [PMID] on the web -- Entrez -- Pubmed" for more details on the publication. |
| i.bait | Integer | 13911416 | Node ID for the protein that was used as a bait in this experiment. Only applicable where the experimental system (see i.method_name) used to support this relationship was a bait-prey system (for example, two hybrid). |
| i.canonical_rig | Integer | 27799 | See notes for the i.rig edge feature. This is the rig constructed for the interaction using its canonical rogs. Use a web browser to query http://wodaklab.org/iRefWeb/interaction/show/27799 (where 27799 is the i.canonical_rig value) to retrieve more information on this interaction and equivalent source interaction records. |
| i.experiment | String | Giot L [2003] | A short label for the experiment where this interaction was found (usually contains authors names). |
| i.flag | Integer | 1 | Used by iRefIndex plugin to control display of edges (0 being the representative edge, used in edge toggle; 1 being an edge which will disappear during edge toggle; 2 being a complex holder edge; 6 being a path; 7 being an edge from or to a collapsed node). |
| i.host_taxid | Integer | 7227 | Indicates the organism taxonomy identifier where the interaction was experimentally demonstrated. |
| i.isLoop | Integer | 1 | Indicates whether the interaction is a self interaction (such as a dimer or possibly multimer of the same protein type). See the source interaction record for details. |
| i.method_cv | String | MI:0018 | PSI-MI controlled vocabulary term identifier for the method used to provide evidence for this interaction. See http://www.ebi.ac.uk/ontology-lookup/ for more details. The name of the method is also given in the i.method_name feature. |
| i.method_name | String | two hybrid | PSI-MI controlled vocabulary term name for the method used to provide evidence for this interaction. See http://www.ebi.ac.uk/ontology-lookup/ for more details. The term identifer is also given in the i.method_cv feature. |
| i.participant_identification | String | predetermined participant | PSI-MI controlled vocabulary term for the participant identification method used to provide evidence for this interaction. See http://www.ebi.ac.uk/ontology-lookup/ for more details. The identifier for the term is also given in the i.participant_cv feature. |
| i.participant_cv | String | predetermined participant | PSI-MI controlled vocabulary term identifier for the participant identification method used to provide evidence for this interaction. See http://www.ebi.ac.uk/ontology-lookup/ for more details. The term itself is also given in the i.participant_identification feature. |
| i.query | String | NP_996224 | The user's query that is responsible for returning this edge. |
| i.rig | Integer | 27799 | Redundant interaction group identifier for the interaction.
This is an integer equivalent of i.rigid. Every rig has one corresponding rigid. |
| i.rigid | String | TAabV6yJ1XzUvEhYwZLpu5reBU0 | Redundant interaction group identifier for the interaction. This is a universal key generated for the interaction by ordering according to ASCII value and concatentating the rogids participating in the interaction and then generating a Base-64 representation of an SHA-1 digest of the resulting string. See PMID 18823568 for details on how this key can be generated. |
| i.score_hpr | Integer | 15 | The hpr score (highest pmid re-use) is the highest number of interactions that any one PMID (supporting this interaction) is used to support. See PMID 18823568 for details. See also i.score_np and i.score_lpr. |
| i.score_lpr | Integer | 11 | The lpr score (lowest pmid re-use) is the lowest number of distinct interactions that any one PMID (supporting this interaction) is used to support. An lpr of greater than 20 is considered to be a high-throughput experiment. See PMID 18823568 for details. See also i.score_np and i.score_lpr. |
| i.score_np | Integer | 2 | Number of PubMed Identifiers (PMIDs) pointing to literature where this interaction is supported. See PMID 18823568 for details. See also i.score_lpr. |
| i.source_protein | Integer | -1 | TO BE DESCRIBED |
| i.src_intxn_db | String | grid | Original interaction database where this interaction record was obtained. |
| i.src_intxn_id | String | 38677 | Original interaction database where this interaction record was obtained.
In some case, it may be possible to right click and "Search [src_intxn_id] on the web -- Interaction databases -- the database" to see the original record. |
| i.type_cv | String | MI:0407 | PSI-MI controlled vocabulary term identifier for the interaction type that occurs between the two proteins. See http://www.ebi.ac.uk/ontology-lookup/ for more details. The term itself is also given in the i.type_name feature. |
| i.type_name | String | direct interaction | PSI-MI controlled vocabulary term identifier for the interaction type that occurs between the two proteins. See http://www.ebi.ac.uk/ontology-lookup/ for more details. The term itself is also given in the i.type_name feature. |
| i.target_protein | Integer | -1 | TO BE DESCRIBED |
User Attributes
Importing - TBD
Searching on - TBD
Obtaining CORUM, DIP and HPRD Data
Due to licensing issues, we are unable to distribute these data with the plugin. CORUM data and free IMex data from DIP will be included in the next public release of iRefIndex.
You can request these data under a collaborative agreement by emailing ian.donaldson@biotek.uio.no
Under the agreement you agree to
- Not redistribute the data outside your research group.
- Provide us with feedback on your use of the data (problems and requests).
We do not require authorship on any related publications.
Obtaining Updates to the Data
You can check for and download updates to the dataset used by your plugin using the Wizard (see "Check for iRefIndex updates").
iRefIndex updates are announced through the iRefIndex Google Group
Obtaining Updates to the Plugin
If you already have a plugin called iRefScape (a menu entry "iRefScape" under the plugin menu of Cytoscape) and you want to make sure you have the latest version, use "Update plugins" from the "Plugins" menu. However, if you want to reinstall the plugin, you should uninstall any previous version of the plugin first.
Plugin updates are announced through the iRefIndex Google Group
Advanced search options
Path-Finding

iRefScape can be used to find interaction events connecting two proteins or a sequence of events involving several proteins.
This process intakes two terminal nodes as input and returns all reasonable paths connecting these two. The results returned here are pathway independent. In other words, the sequences of interactions connecting the nodes are not constructed using currently published pathways. However, the paths returned may contain pathway centric information.
The query format is as follows:
NP_004976 <==> NP_002871
Additional type and taxonomy parameters were also supplied as required:
- Search type: RefSeq_Ac
- Taxonomy: 9606 (Homo sapiens)
This query located all reasonable paths between NP_004976 and NP_002871 and the returned path also contains the shortest path between them. The results of the path finding was sorted in the ascending order of path length and the maximum path length was restricted to a default value of 6; this value can be modified by changing the value of "Maximum distance" from the "Path parameters" tab in the advanced options panel. The paths found in this way were "reasonable paths", this concept is different from finding the shortest path or finding all the paths. A "reasonable path" from A to B is a path extending from A to B where none of the intermediate points can be reached from A with fewer steps by a path that extends from A via B (in other words, when evaluating a path from A to B, nodes beyond B are not considered).
Reversing the Path

Due to the way the algorithm works, when the opposite search was performed...
NP_002871 <==> NP_004976
...it took 120 seconds and returned 3 paths. The reason for this is that NP_002871 is directly connected to many hubs and therefore, the initial seed-list size was larger than when starting with NP_004976. The algorithm first tries the direction requested by the user and after that considers the opposite direction when creating the sub-network to look for the path. The time consuming step in the opposite search (NP_002871<==>NP_004976) is thus the initial evaluation step. When constructing the query for path-finding we used the attribute i.overall_degree_TOP and it provided the overall connectivity of the proteins within iRefIndex. The i.overall_degree_TOP value of RAF1 was found to be 443 and for the KRAS isoform was found to be 2. Therefore, although not shown in the graph, RAF is connected to more than 400 other proteins than RAS1.
In the image shown here, the green arrow shows the path.
Path Selection

After the path-finding is completed the "Path selection" panel can be used to selectively load the paths. In order to make the selection easier, the paths found can be described by a particular attribute type: by selecting a value from the list for "Convert pop-up type to" (such as RefSeq_Ac) and pressing the "Convert" button, a tooltip appearing over each path description will show the requested attribute values for each component of the path. Thus, a path description such as...
321631 -> 2229473 -> 4410739 -> 4531114
...will provide a tooltip showing the following identifiers:
NP_002871 -> NP_001123914 -> NP_036979 -> NP_004976
List comparison
This feature is available with version 0.91 and later.
This feature provides a way to compare two lists of proteins. When a "COMPARE{<List1>,<List2>}" format query is issued with default settings an interaction network is loaded with interactions involving only the proteins of the list and proteins which are not in the list but interacts with at least two proteins from each list (intermediate components). At the end of the operation, in addition to the Cytoscape network a adjacency cube (adjacency matrix with colours as the third dimension) is also created. This adjacency cube is synchronized with the network and can be used examine the results easily. A summary report function is provided to list the overall summary of each protein in the list sorted order so that the most connected protein appear first. The identifiers used to display the proteins in the adjacency cube are either iROGID or the ROGID of complexes. The user has the option to visualize these in popular identifier types using convert feature.
Example query.
COMPARE{P08588,P16671|P07550,P13945} (Example from PMID:20670417)
This query compares two groups. Group 1 = P08588,P16671 Group 2 = P07550,P13945
Members within the group are separated with a comma (",") Groups are separated by a pipe ("|").
Q&A fore list comparison
- Q. What is the maximum number of members a group can have ?
- A. You could have any number of members, more members there are more time it will take for the operation and more memory it will need. Fro instance the above example search will complete comfortably in 1 minute with 256Mb of allocated memory. If you have more than 100 members we recommend having at least 1Gb dedicated memory for Cytoscape.
- Q. Can I compare more than two groups.
- A Yes , each group should be separated with a pipe character. Maximum number of recommended group count is 255.
- Q What if a protein or protein resulting from query appears in more than one group ?
- A All proteins found in more than one group is treated as a new group.
- Q. Can I compare members of already grouped identifier ?
- A. Yes. As an example if you want to compare interactions among the disease group 141, the following query could be used.
COMPARE{141}
Troubleshooting
- See http://cytoscape.org/ for a manual and a set of tutorials which describe the installation and use of Cytoscape.
- For problems with Cytoscape installation or use, try the Cytoscape Help Desk
- If you have problems with installation or use, please share your experience with us through the iRefIndex Google Group
- When updating data on Microsoft Windows XP and Vista, a "Failed to find resources message" may appear in the log message window. If this happens please run the update again and the plugin will check and correct the problem during the second attempt.
- If you are working with large graphs, make sure Cytoscape has at least 128MB memory. See the following document for more information on setting up memory: http://cytoscape.org/cgi-bin/moin.cgi/How_to_increase_memory_for_Cytoscape
All iRefIndex Pages
Follow this link for a listing of all iRefIndex related pages (archived and current).